Please wait, while the deck is loading…
 - Authors: Valentina Zantedeschi, Rémi Emonet, Marc Sebban
- Date:
- Lille - Magnet Team
- Authors: Valentina Zantedeschi, Rémi Emonet, Marc Sebban
- Date:
- Lille - Magnet Team
for a sample $S$ of $m$ instances $(x_i,y_i)$
- $\theta$, $b$ the parameters of the linear separator - $\mu$ a mapping function, so that $\mu(x_i)^T\mu(x_j) = K(x_i,x_j)$
In Brief
- Learning a classifier from a fully labeled setIssues
- Label assignment is difficult and expensive: - difficult: unique and reliable labels - expensive: great amount of data, need for experts - Datasets are generally noisyHow to handle the confidence in the labels? ## Weak-Label Learning labels are incorrect, missing or not unique
Sub-problems
- Semi-Supervised Learning - Unsupervised Learning - Label Proportions Learning - Multi-Instance Learning - Multi-Expert Learning - Noisy-Tolerant Learning ## Empirical Surrogate $\beta$-RiskFor any margin-based loss function $ F_{\phi} $
$\beta$ degree of confidence / probability of labels $\beta_i^{\text{-}1} \in [0,1]$, $\beta_i^{\text{+}1} \in [0,1]$ $ \beta_i^{\text{-}1} + \beta_i^{\text{+}1} = 1 $
Margin-based loss functions
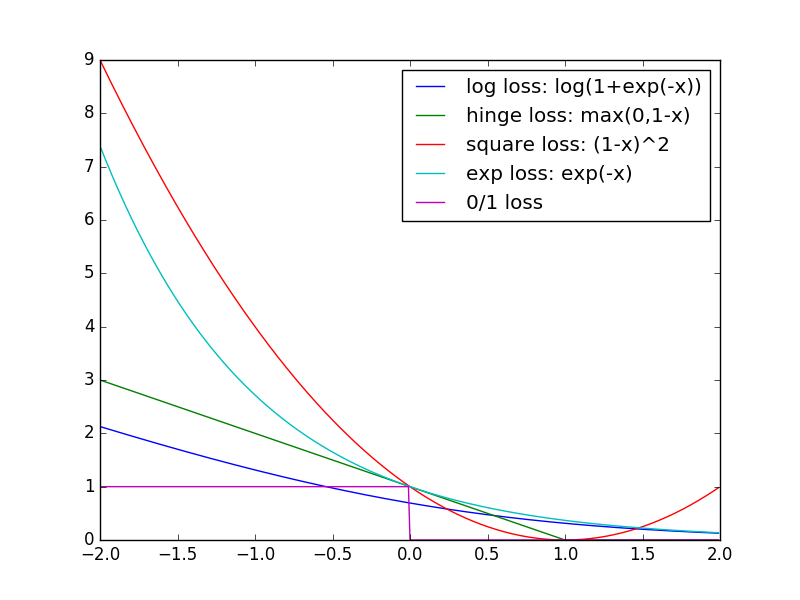
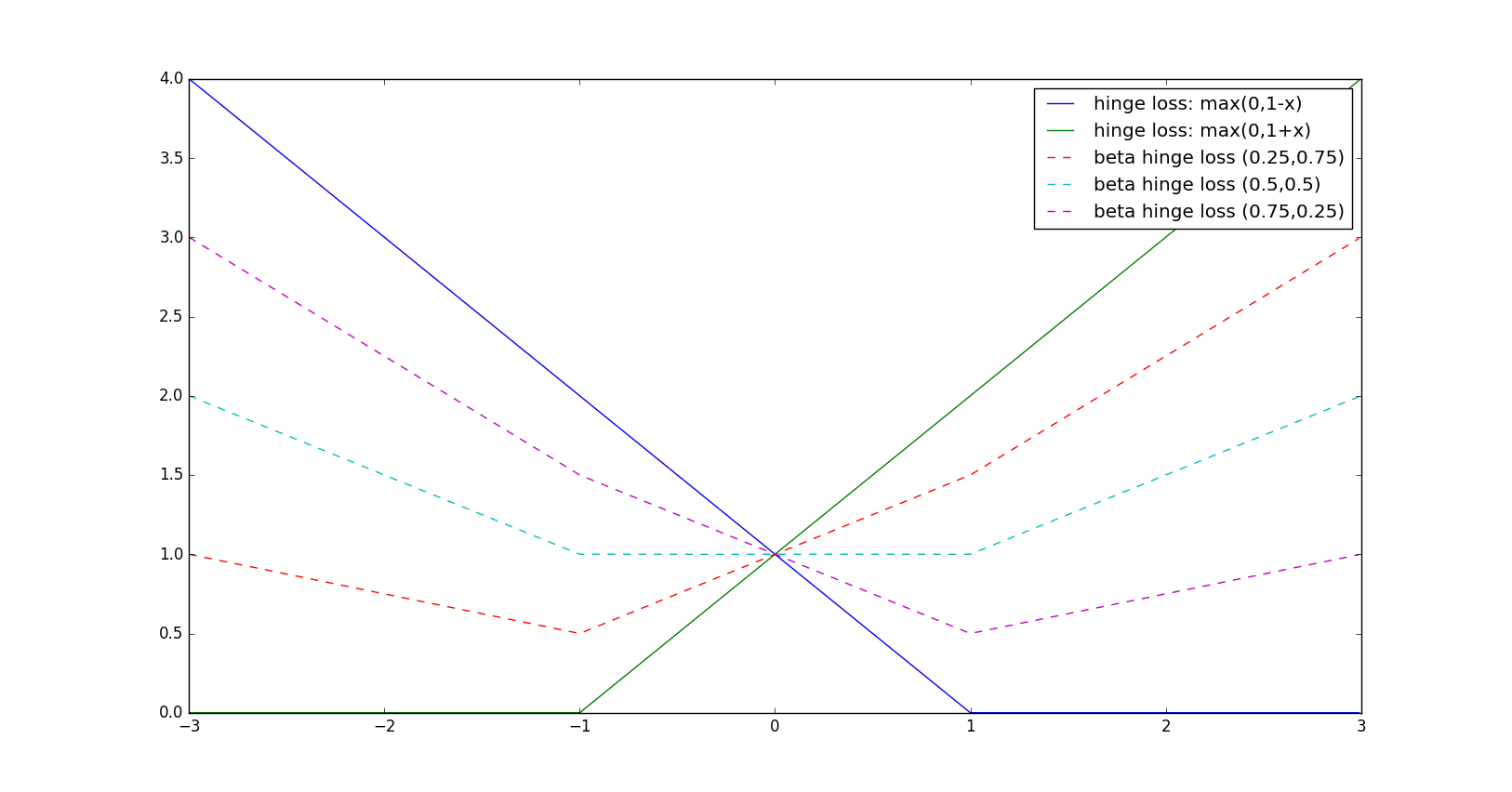
primal problem
 ## Relation with the Classical Risk
## Relation with the Classical Risk
Let's rewrite the classical risk
- R_{\phi}^{\beta}(X,h) is the $\beta$-risk - \frac{1}{m} \sum_i \beta_i^{-y_i} y_i h(x_i) is a penality term on the missclassified instances ## Iterative Algorithm
1. Learn $h$
$s.t.\: \sum_{i=1}^{m}\beta_i^{\text{-}y_i} y_i h(x_i) = 0$
$\beta_i^{\text{-}1} + \beta_i^{\text{+}1} = 1$
with $m_l$ labeled instances and $m_u$ unlabeled instances
1. Initialization of $\beta$ - $\forall i=1..m_l \:\: \beta_i^{\sigma} = 1 \:\text{if}\: \sigma = y_i, 0 \:\text{otherwise} $ - $\forall i=m_l+1..m_u \:\: \beta_i^{\sigma} = 0.5$ 2. Iterative Algorithm - Learning $\beta$ of unlabeled set ## Results
 WellSVM:
Li Yu-Feng, Tsang Ivor W, Kwok James T, Zhou Zhi-Hua.
Convex and scalable weakly labeled SVMs
The Journal of Machine Learning Research, 2013.
## Perspectives: Differential Privacy
How to accuratly learn while preserving the user privacy?
Learn on bags of instances:
- the labels of each single instance are unknown
- we have access to the proportions of the classes per bag
# Thanks for your attention
WellSVM:
Li Yu-Feng, Tsang Ivor W, Kwok James T, Zhou Zhi-Hua.
Convex and scalable weakly labeled SVMs
The Journal of Machine Learning Research, 2013.
## Perspectives: Differential Privacy
How to accuratly learn while preserving the user privacy?
Learn on bags of instances:
- the labels of each single instance are unknown
- we have access to the proportions of the classes per bag
# Thanks for your attention
/ − − automatically replaced by the title
← →