Please wait, while the deck is loading…
 - Author:
- Supervisors: Rémi Emonet and Marc Sebban
- Date:
- Author:
- Supervisors: Rémi Emonet and Marc Sebban
- Date:
Metric Learning
Optimization Problem with similar/dissimilar pairs
\mathrm{arg}\min\:\sum_{m,n} s_{mn}d_A(x_m,x_n) + \lambda \left \|A \right \|^2_F
s.t. \: \sum_{m,n} (1-s_{mn})d_A(x_m,x_n)\geq 1
s.t. \: \sum_{m,n} (1-s_{mn})d_A(x_m,x_n)\geq 1
 where s_{mn} =
\begin{cases}
1, & \text{if } x_m, x_n \text{ are similar}\\
0, & \text{otherwise}
\end{cases}
where s_{mn} =
\begin{cases}
1, & \text{if } x_m, x_n \text{ are similar}\\
0, & \text{otherwise}
\end{cases}
Metric Functions examples
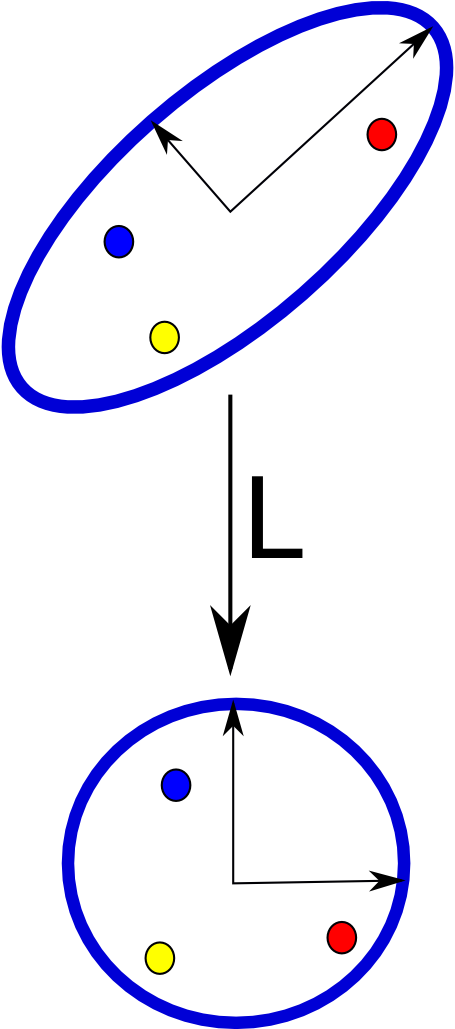
Mahalanobis Distance
d_A(x_m,x_n) = \sqrt{(x_m-x_n)^TA(x_m-x_n)}given
- x_m,x_n two points
- A = S^{-1} (S = covariance matrix)
- A is Positive Semi-Definite (A\succeq0)
- A = L^TL d_A(x_m,x_n) = \sqrt{(x_m-x_n)^TL^TL(x_m-x_n)} = \sqrt{(L(x_m-x_n))^T(L(x_m-x_n))}
Metric Functions examples
given two points x_m, x_n

Cosine Similarity
d(x_m,x_n) = \frac{x_m x_n}{||x_m|| ||x_n||} = cos(\theta)Bilinear Similarity
d_A(x_m,x_n) = x_m^TAx_n
Non-linearities and Multi-modalities
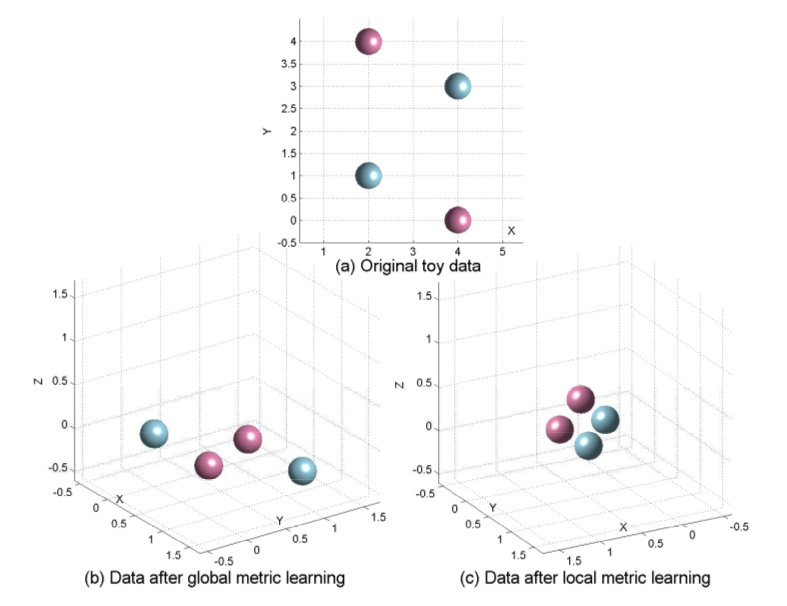 Huang, Yinjie, et al. "Reduced-rank local distance metric learning." in Machine Learning and Knowledge Discovery in Databases 2013
## Local Metric Learning
Huang, Yinjie, et al. "Reduced-rank local distance metric learning." in Machine Learning and Knowledge Discovery in Databases 2013
## Local Metric Learning
Which metric to use?
Local Metric Learning
- Kmeans clustering based on Euclidean distance
- Regression of metrics
- K local metrics
- 1 global metric
+ easy to learn
+ local metrics capture well the underlying geometry of the input space
- high risk of overfitting
- global metric is not enough accurate
+ local metrics capture well the underlying geometry of the input space
- high risk of overfitting
- global metric is not enough accurate
Perrot Michaël, Amaury Habrard, Damien Muselet, and Marc Sebban. "Modeling Perceptual Color Differences by Local Metric Learning." In Computer Vision–ECCV 2014
Convex Combinations
* defined on a clusters' pair $(R_i,R_j)$ * described by a vector $W_{ij} \in \mathbf{R}^K$ representingthe influence of each local metric
$d_{ij}(x_m,x_n) \:=\: \sum_{z}W_{ijz}d_{M_z} (x_m,x_n)$

Convex Combinations of Local Metrics
Learning Process
KMeans based on Euclidean distance
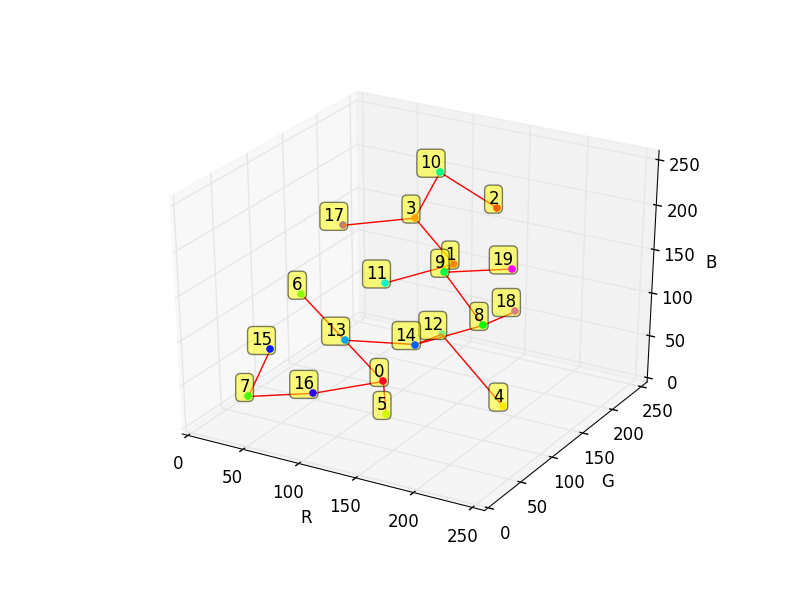
between clusters' centers
Find M_z for each cluster
\mathrm{arg}\min_{M_z\succeq0}\:\frac{1}{n_z}\sum_{m,n \in C_z}\left \| d_{M_z}(x_m,x_n) - y(x_m,x_n) \right \| + \left \|M_z \right \|^2_F
Regularization of the Optimization Problem
Topological Characteristics of the Space's Decomposition
D(W) = \sum_{i=1}^{Z}\sum_{j=1}^{i-1}\left \| E_{ij}.W_{ij} \right \|_{F}^2

E_{65} = \left( \begin{array}{ccc}
4 \\
6 \\
4 \\
6 \\
2 \\
2 \\
2 \\
8 \\
...
\end{array} \right)
Algorithmic Robustness
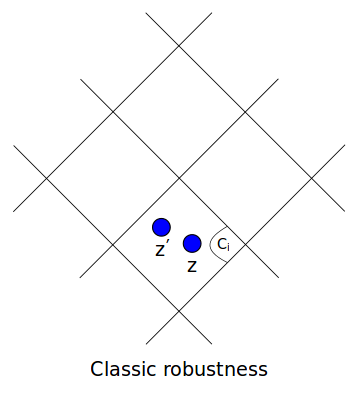 Bellet Aurélien and Amaury Habrard. "Robustness and generalization for metric learning." Neurocomputing 151 (2015)
## Theoretical Guarantees with Mahalanobis Distances
for any $\delta > 0$ with probability at least $1-\delta$:
Bellet Aurélien and Amaury Habrard. "Robustness and generalization for metric learning." Neurocomputing 151 (2015)
## Theoretical Guarantees with Mahalanobis Distances
for any $\delta > 0$ with probability at least $1-\delta$: $ | R^l - \hat{R}^l | \leq$ $2 \left \|L \right \|_2 \gamma_1 + \gamma_2$ $+$ $B \sqrt{\frac{2H\ln2 + 2\ln{1/\delta}}{n}}$
with - $L$: $M_z = L^TL$ - $\gamma_1$: the radius of the regions defined on the input space - $\gamma_2$: the radius of the regions defined on the output space - $H$: number of regions defined on the input space - $n$: number of instances - $B$: the upper bound of the loss function
Applications and Results
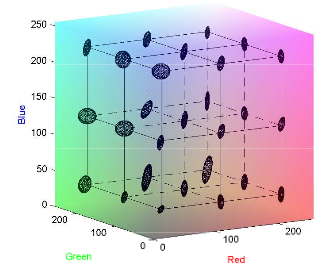
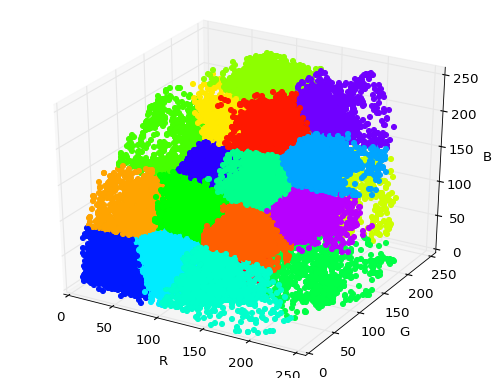
Perceptual Color Distance

 on RGB space
on RGB space
Applications and Results
Perceptual Color Distance Estimation
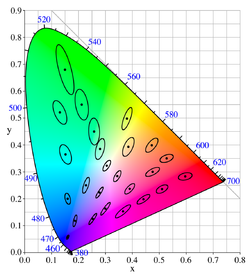
Tolerance
the set of points whose distance to the reference is less than the just-noticeable-difference threshold
can be seen as a set of Mahalanobis metrics
Applications and Results
Perceptual Color Distance Estimation
Generalization on unseen colors
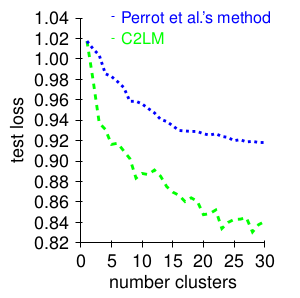
Generalization on unseen cameras
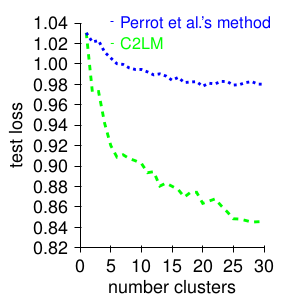
Applications and Results
Semantic Similarity Estimation
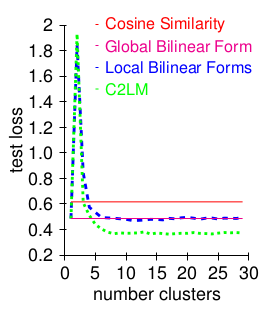
Word Embedding computed using Hellinger PCA
Lebret Rémi and Ronan Collobert. "Word emdeddings through hellinger pca." arXiv preprint arXiv:1312.5542 (2013)
Lebret Rémi and Ronan Collobert. "Word emdeddings through hellinger pca." arXiv preprint arXiv:1312.5542 (2013)
Convex Combinations of Local Metrics
Learning Convex Combinations
S(W) = \sum_{i=1}^{Z}\sum_{j=1}^{i}\sum_{{i}'=1}^{Z}\sum_{{j}'=1}^{{i}'}K_{ij{i}'{j}'}\left \| W_{ij} - W_{{i}'{j}'}\right \|_{2}^2
K_{ij,{i}'{j}'} = e^{-min(d_{i{i}'}+d_{j{j}'},d_{i{j}'}+d_{j{i}'})}
K_{56,77} = e^{-2}
K_{56,89} = e^{-9}
/ − − automatically replaced by the title
← →